Machine Learning, Intelligence Artificielle, Data Science… Il est parfois difficile de s’y retrouver dans le jargon du « monde de la data ». Nous avons développé pour vous dix concepts incontournables qui vous aideront à comprendre les conversations sur ces sujets.
0. Data set (jeu de données)
Commençons par la matière première : 👉 la donnée 👈.
Un jeu de données est un ensemble d’observations 👀 . Ces observations peuvent être des enregistrements sonores, des photographies, des documents textuels ou encore des caractéristiques d’individus observés (taille, poids, âge par exemple) etc.
Dans un jeu de données bien structuré, les observations ont toutes le même format et peuvent ainsi être traitées de la même façon 👍.
0 bis. Algorithme / Input / Output
Un algorithme est une suite finie et non ambiguë d’opérations permettant de résoudre un problème 🤯 .
On appel input l’ensemble des informations de départ et output le résultat de l’algorithme.
1. Machine Learning / Intelligence Artificielle


2. Data Scientist / Data Engineer / Data Analyst
-
le Data Scientist est le plus matheux des trois : son métier est de concevoir des algorithmes à travers l’analyse automatique de données (l’apprentissage)
-
le Data Engineer est celui qui rend la donnée accessible, la structure, intègre le travail du Data Scientist dans le logiciel, assure le contrôle qualité, gère l’infrastructure, le déploiement de nouvelles versions, la maintenance etc.
-
le Data Analyst, comme le Data Scientist, travaille sur les données mais sans objectif d’en faire sortir un algorithme : il cherche à faire ressortir de l’information afin qu’elle soit utilisée par des humains dans des prises de décision. Pour y parvenir au mieux, il doit être capable de présenter ses analyses de la façon la plus limpide possible en se servant d’outils de Data Visualisation. Son bagage en mathématiques peut être plus réduit que celui du Data Scientist et son bagage en programmation et infrastructure peut être plus réduit que celui du Data Engineer ; mais le Data Analyst doit absolument être un bon communicant et avoir une forte capacité de synthèse et de présentation.
3. Training ou learning (entraînement ou apprentissage)

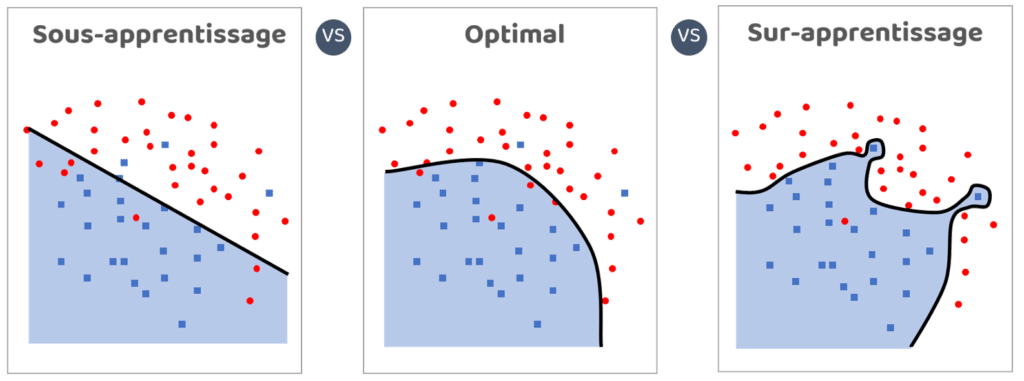
4. Surapprentissage (overfitting)
5. Training set / Validation set / Testing set
(jeu d'entraînement / jeu de validation / jeu d'évaluation)
- le training set 🤨 sert à l’apprentissage : c’est le seul jeu de données qui doit être donné aux algorithmes et sur lequel le Data Scientist doit s’appuyer pour concevoir son modèle.
- le validation set 👍 est là pour évaluer les modèles au fur et à mesure de l’apprentissage et pour comparer des algorithmes différents ou différemment paramétrés. On a besoin d’un jeu de données distinct du training set pour être sûr de ne pas valoriser des algorithmes qui s’appuient sur les particularités du training set (i.e. overfiter)
- le testing set 💪 est là pour évaluer une seule fois le modèle choisi à la fin et attribuer un score fiable au modèle retenu. Le validation set ne peut être utilisé pour cela car il a servi à choisir le meilleur algorithme (autrement dit, l’algorithme choisi est adapté à lui); il y aurait donc un risque de suraprentissage 🛑.
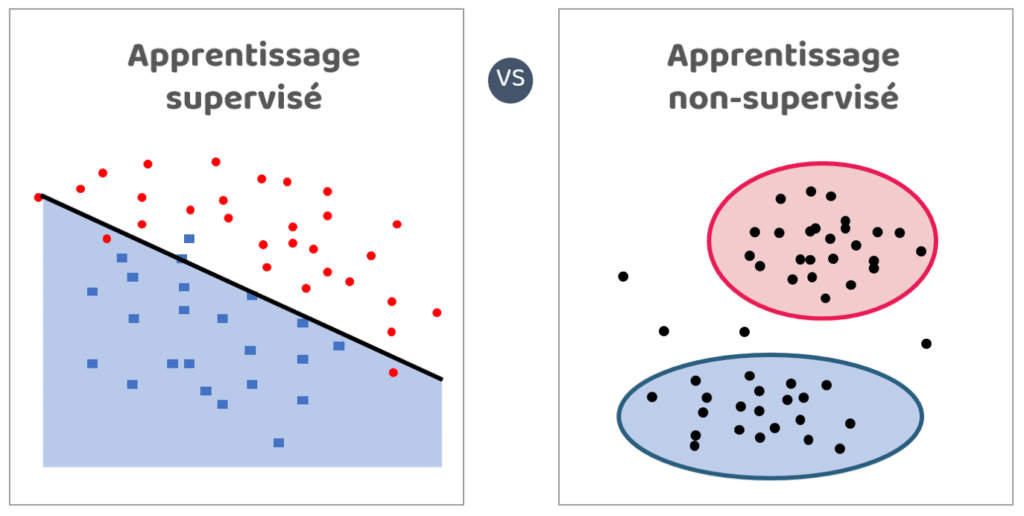
6. Apprentissage supervisé / non-supervisé
7. Feature / Feature engineering
👉 Par exemple : prenons un dataset constitué d’individus. La couleur des yeux 👀 et le poids sont des features très simples. Le nombre moyen de légumes 🥦consommés par semaine ou bien la durée médiane du temps de trajet quotidien 🛴 sont d’autres features, plus complexes.
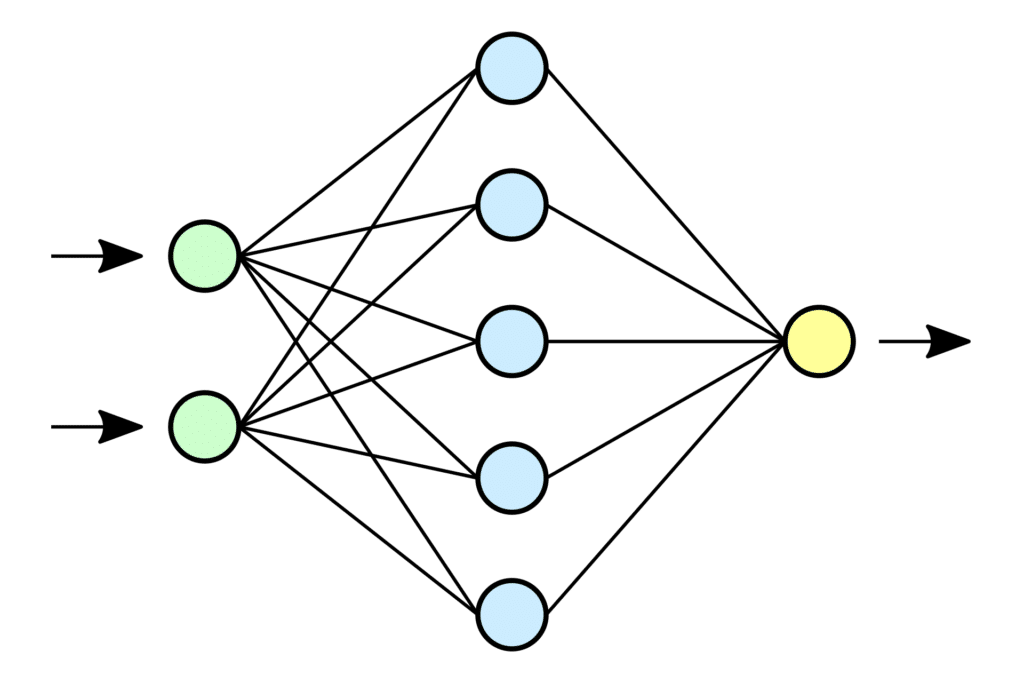
8. Réseau de neurones (neural network) / Deep Learning
9. Data leak

10. Data Lake / Data Warehouse
Un Data Lake est un espace de stockage destiné à accueillir toutes les données qu’il peut être utile d’accumuler.
On y stocke les données brutes 🔧 comme les données structurées 💿 contrairement au Data Warehouse, qui est la version propre du Data Lake. On y stocke uniquement les données prétraitées et structurées 💿💿💿 en vue de leur utilisation future.
——
Suivez moi sur Linkedin pour plus de contenu comme celui-là: Marc Sanselme


