Machine Learning, Artificial Intelligence, Data Science… It is sometimes difficult to navigate the jargon of the “data world”. We have developed ten essential concepts for you that will help you understand conversations on these topics.
0. Data set
Let's start with the raw material: 👉 la given 👈.
A dataset is a set of observations 👀 . These observations can be sound recordings, photographs, textual documents or even characteristics of observed individuals (height, weight, age for example) etc.
In a well-structured dataset, the observations all have the same format and can therefore be processed in the same way 👍.
0 bis. Algorithm / Input / Output
An algorithm is a finite and unambiguous sequence of operations to solve a problem 🤯.
We call input all the initial information and output the result of the algorithm.
1. Machine Learning / Artificial Intelligence


2. Data Scientist / Data Engineer / Data Analyst
-
le Data Scientist is the most maths of the three: his job is to design algorithms through automatic data analysis (learning)
-
le Data Engineer is the one who makes the data accessible, the structure, integrates the work of the Data Scientist in the software, ensures the Quality Control, manages theinfrastructure, the deployment of new versions, maintenance etc.
-
le Data Analyst, like the Data Scientist, works on the data but without the objective of producing an algorithm: he seeks to make get out the information for use by humans in decision making. To achieve this as best as possible, he must be able to present his analyzes as clearly as possible by using Data Visualization. Their background in mathematics may be less than that of the Data Scientist and their background in programming and infrastructure may be less than that of the Data Engineer; but the Data Analyst must absolutely be a good communicator and have strong synthesis and presentation skills.
3. Training or learning

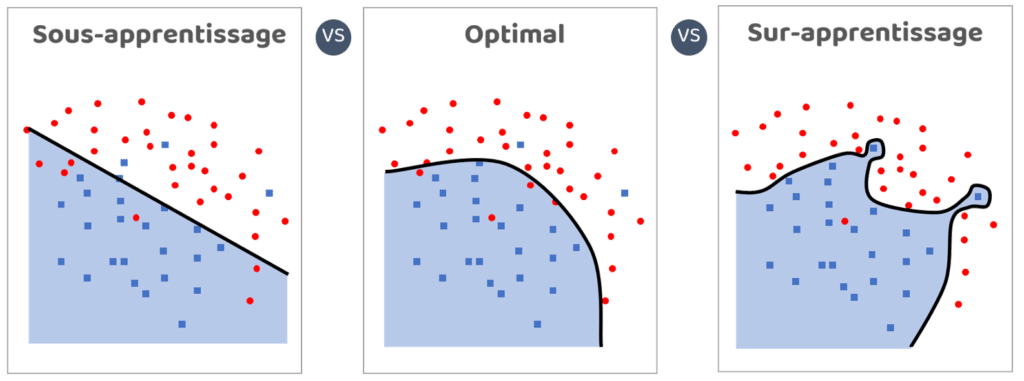
4. Overfitting
5. Training set / Validation set / Testing set
(training game / validation game / evaluation game)
- le training set 🤨 serves to learning : this is the only data set that must be given to the algorithms and on which the Data Scientist must rely to design his model.
- le validation set 👍 is here to assess the models As things progress of learning and for can compare different or differently parameterized algorithms. We need a dataset separate from the training set to be sure not to use algorithms that rely on the particularities of the training set (ie overfit)
- le testing set 💪 is there for evaluate the chosen model only once end and assign a reliable score to the selected model. The validation set cannot be used for this because it was used to choose the best algorithm (in other words, the chosen algorithm is adapted to it); there would therefore be a risk of overlearning 🛑.
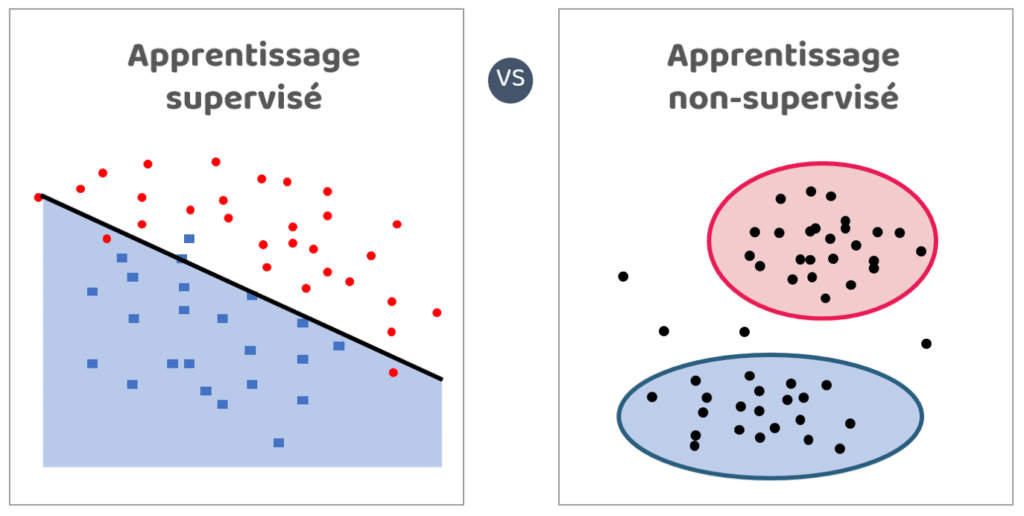
6. Supervised / unsupervised learning
7. Feature / Feature engineering
👉 For example: let's take a dataset made up of individuals. Eye color 👀 and weight are very simple features. The average number of vegetables 🥦consumed per week or the median duration of daily travel time 🛴 are other, more complex features.
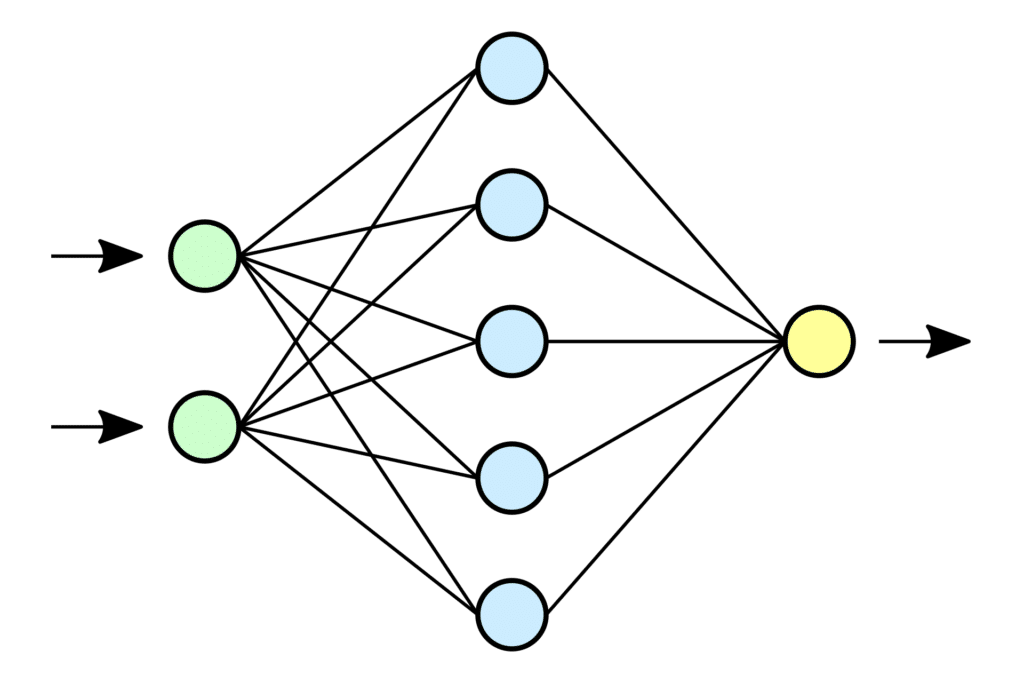
8. Neural network / Deep Learning
9. Data leaks

10. Data Lake / Data Warehouse
A Data Lake is a storage space intended to accommodate all the data that may be useful to accumulate.
Data is stored there raw 🔧 like data structured 💿 unlike the Data Warehouse, which is the clean version of the Data Lake. Only data is stored there pre-processed and structured 💿💿💿 for their future use.
-
Follow me on Linkedin for more content like this: Marc Sanselme


